

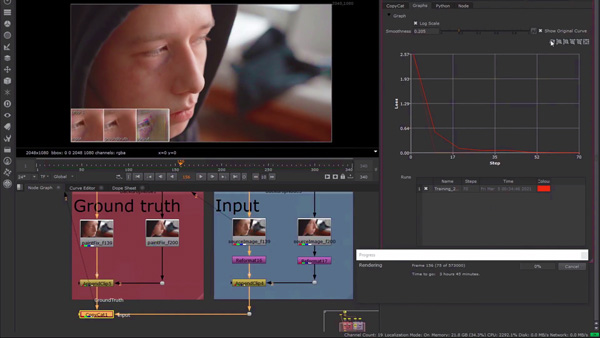
In March 2021, Foundry introduced machine learning into Nuke 13.0 with the addition of the CopyCat node, a tool that takes the process of building custom tools beyond scripting, Python extensions and SDKs. CopyCat hands users a process whereby they can show a network exactly what needs to be done to complete a task, how it should be done and to what standard.
Starting with reference frames from a sequence, artists can use the CopyCat node to train neural networks to automatically complete tasks ranging from rotoscoping, clean-up and beauty work, to correcting focus and other camera effects. The artist inputs a selection of the original frames, each matched to a frame showing what he or she wants them to look like, called the Ground Truth, and effectively trains a network to replicate the desired effect across all frames in a shot.
Training neural networks to work on video is an application of machine learning (ML) that the software developers at Foundry have been interested in for some time. Digital Media World had a chance to speak to Foundry’s Head of Research Dan Ring about the history of ML at Foundry, what they are working on within this field now, and what directions they plan to take it in the future.
From Research to Studios – Bridging the Gap
Foundry’s research team launched a project in 2019 called ML Server – an open source academic exercise for users to test. One of its goals was to determine the level of interest that exists in their market for machine learning. Dan said, “ML isn’t a new development, and many people are still thinking in terms of ‘deep learning’, layers of operations stacked on top of each other to mimic human neurons. So far, the way human neurons work has proven incredibly complex to recreate, but the research being devoted to tasks that rely on image recognition has been more promising.”
“That research led to thinking about image-based tools for compositing. Images are a dense source of precise information, and image recognition is a common element of VFX work and editorial. Furthermore, creating masks base on images is a major element of compositing. However, bringing the findings of academic research into practical applications has been difficult, and bridging that gap was a further motivation behind ML server.”
For instance, the computation and code for academic applications and experimentation don’t have to be extremely robust, whereas to be useful in VFX applications, coding has to perform consistently in virtually any situation. ML Server helped define practical constraints as well, such as graphics hardware requirements, which operating systems were relevant and what interests artists the most about ML for their work today.
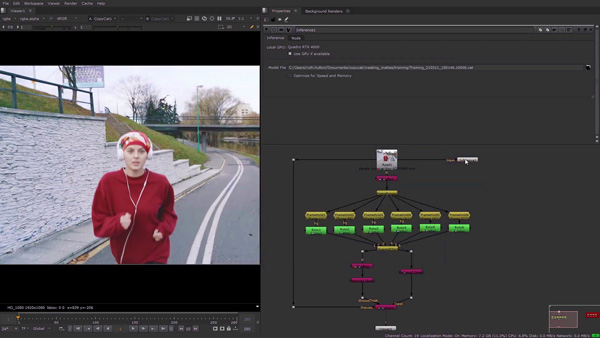
CopyCat can be used to create a precise garbage matte for the woman in this video. (See the image below.)
Supervised Learning
As a consequence of that project, Foundry felt compelled to put ML into a set of tools that artists could use in their own way to solve their own problems. “Foundry did not want to be sitting in the middle of, or interfere with, that problem-solving process. Instead, the purpose of CopyCat is to allow artists to train a neural network to create their own sequence-specific effect in Nuke.”
At the simplest level, ML is supervised learning. You have some data you want to use to develop a model to achieve a certain task. So you go through a process of training, assessing the results and refinement. For the model, learning at this level happens largely through making mistakes and being corrected.
To address the challenge of transferring that process to VFX production, we can use the model’s ability to improve itself and, more specifically, to improve by doing the task your way. “Here is the data I have, HERE is what I want you to pull from it.” An example of a practical application would be - “I give you an input image, you give me a useful mask based on that. I’ll show you some examples of what I mean by a mask, and then you create a network that can generate a mask from any of the other frames.”
Shot-Specific
This was the premise behind Foundry’s ML Server. In fact, the pool of artists who were testing the program loved using it. Even though it wasn’t quite ready for production yet, they started trying to use it in production anyway. Once they understood that users do want access to ML in their software, Foundry wanted to find out exactly what they were using ML Server for. That was where CopyCat node came from – the result of transferring those capabilities into Nuke as native functionality.
“The core principle of the node is based on take an image from your source media, and then giving it to the system with a specially created frame – for example, a keyframe – as an ideal outcome,” said Dan. “Once you have given it several more examples – in the tens, not hundreds – the network will then try to copy your work across all frames as it continues to develop, but in a manner generalised only as far as that shot extends as defined by your samples. In other words, the system will be shot-specific.
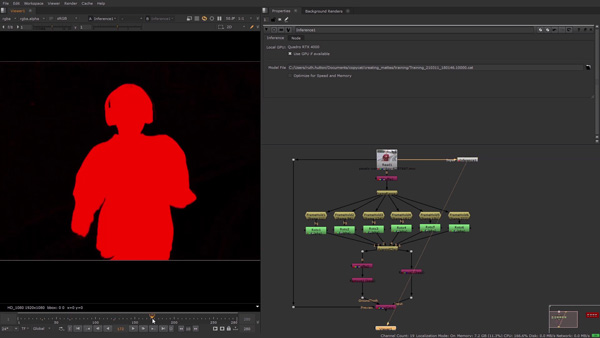
“That is a key difference between CopyCat and a traditional ML model. No generalising is done for the wider world. You are training this limited-application model for just what you are doing right now. This approach allows artists to work at scale, accelerating their work with the option to use the same trained network on multiple sequences.”
Inference
The CopyCat tool consists of two nodes. Training networks is done with the CopyCat node – you give this node your example pairs and generate a .cat file. But while this node has intimate knowledge of the training pairs and the relationship between the two images in each one, that is all that the .cat file knows about. To do actual work, it has to be passed on to the Inference node, which applies the .cat file’s knowledge across the rest of the frames to create the effect modelled by the network.
Foundry split these functions for two reasons. One is hardware efficiency. The learning process that builds the knowledge into the .cat file takes more compute power than applying the effect. After that huge learning effort, the Inference node can in fact run on a laptop.
Dan said, “Another reason for separating the CopyCat node from Inference is to make the .cat file more flexible and recognise its value as a piece of IP in itself. Nuke has native support for your .cat file, and many existing models trained in other software can be saved as .cat files as well by adding certain types of metadata. Both can be used in Nuke with the Inference node.
The Value of an Artist
“Instead of working as a predefined tool that does only one thing, CopyCat puts machine learning within reach of an artist’s imagination and can therefore do lots of things, depending on that artist.” This process empowers artists, but can’t replace them because the trainer is the artist, not the model. The artist is isolating the tedious, repetitive portions of the work and teaching the model how to complete those portions to the necessary standard.”
The idea that artists will somehow lose out through the adoption of ML tools is obviously of primary concern. A roto artist working manually will normally finish 60 to100 frames day, and thus a 200 frame sequence might take two the three days. Using ML can bring that down to two hours.
However, Dan also said, “One thing that our rotoscoping example highlighted to us was the value of the artists we were working with. A good roto artist can elevate a shot to something beautiful and totally believable. It takes a long time and enormous skill to be really good at the work and, therefore, to be able to train a model effectively. As the network can only imitate the style of its trainer – precise and conscientious, or haphazard and inconsistent – the work needs a good artist as well as someone who can select the most relevant series of reference pairs.”

Beauty repairs achieved with CopyCat.
Applications
Another application Foundry has tested with CopyCat is beauty repairs, which can be labour-intensive due to subtle changes in lighting that may occur across frames, or to shifting camera angles. Artists can remove beards, tattoos, bruises and scars this way.
An even more valuable application is correcting focus issues in video, for example, bringing a blurred shot into focus. The artist searches through the video to find the frames, or even just parts of frames, that are focussed correctly. As before, show the network before/after pairs, as in the roto mask and beauty examples, and ask it to discover relationships between the source material and the desired outcome.
“If the network turns out a bad frame or two during training, you don’t have to re-start the process, said Dan. “The system is cumulative, incrementally building up expertise. You can just correct the bad frames in the same way as the others, and add them to the training file – that is, the .cat file – of before/after pairs. The system will continue from there.”
Creativity
The other, critical side of artists’ contribution to projects is creativity. Networks and models are capable of extreme consistency – that is what they are good at and what CopyCat takes advantage of. Creativity comes from elsewhere.
Masking, beauty work and re-focussing have traditionally been hugely time-consuming, costly issues for compositing. The cost comes not only from having to pay for hours of manual work, but also from missing out on creative ideas that never had a chance to be developed ahead of deadlines.
“That potential was evident when Foundry found that the artists testing CopyCat were using it for a much wider variety of interesting, specific tasks – de-aging, animation corrections and anything that benefits from a repetitive, automated approach and absolute consistency. Training a tool to detect and flag animation errors, or even go on to fix them, at the QC stage is a use case with a lot of scope that just needs creativity to expand,” Dan noted.
Extensibility and Data Quality
Foundry’s developers want to develop scope for extensibility in CopyCat for artists who train networks, whether these be .cat files originally built in CopyCat or others. They especially want to encourage artists to bring their own models to the pipeline, not just bring data to Nuke and wait for an algorithm to be developed for them.
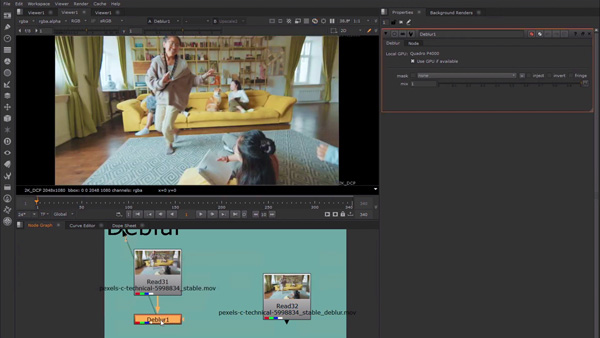
Training a model to de-blur video.
“But it has to be done properly, just as developers have done with their C++ SDKs for Nuke, scripting and Python Nuke extensions,” Dan said. “These now have conventions for use as part of Nuke. We’re aiming to do something similar for users’ ML models as part of our effort to bridging the gap between academic research and production."
The high quality of the data that VFX artists give their networks also gives them a head start in terms of training time and use-specific tools. Video from media & entertainment projects usually has a high dynamic range and resolution, accurate lighting properties and approval from a director and DP. In the past, neural networks were set up to chew through large volumes of relatively low quality, available images, and could take a long time to train into a workable model. When it comes to creating useful tools, however, starting with a good artist and good data will shorten training time.
VFX Wish-list
“VFX studios have fantastic data sets for training networks. Foundry wants them to know that they already have the means to train models for many applications. We don’t have that data ourselves, but have developed CopyCat to help them take advantage of those data sets. The quality of their data, combined with their artists’ skills, can make them more competitive," said Dan.
Ultimately, tools like CopyCat will not remove artists’ jobs – it will make VFX work more creative. Today’s short timeframes mean the wish-lists associated with jobs may only ever be 40 percent completed. With ML, teams may be able to get to 60 percent of items on those lists. ML gives a studio an opportunity to move past the busy work and solve the harder problems, squash repetitive tasks and move on to the creative faster. It may also mean VFX artists have a new skill to acquire – quickly and efficiently training neural networks.
Smarter Roto
Dan also talked about how Foundry will continue to progress the use of ML in its software. An on-going project with University of Bath and DNEG, called SmartROTO, addresses issues of correcting models in the course of training. They wanted to figure out how best to correct the model by telling the system, in a meaningful way, that it’s not working so that it understands its work has fallen short of the goal, appreciates the problem and tries to improve its work.
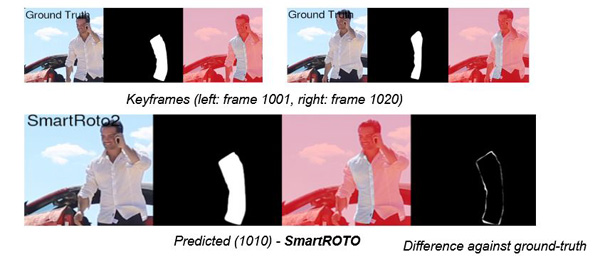
Training networks to recognise arbitrary shapes that change over time requires interactivity.
He said, “It called for something more interactive than preparing a new ‘after’ frame and making sure that all feedback is detected, interpreted and applied correctly. We needed to give the network a region of ‘correctness’ and developed two models, Appearance and Shape, both of which test whether a given image is visually similar to the desired outcome. But they test for that in different ways.
“The Appearance model determines whether a given arrangement of pixels looks like something we've seen before, while the Shape model constrains the set of possible matches, saying 'force the current silhouette to match a silhouette I've seen before'. Typically, ML models for images only use Appearance models, that is, they're given an image patch and asked to classify or transform it – for example, determining whether or not an image contains a dog.“
Appearance models work well in most cases, but have no meaningful concept of the shape or structure of the element being worked on, which is much more important for roto. The Shape model encodes this idea of structure, and validates what the Appearance model has found.
“If we are rotoscoping an arm, it will only encourage arm-like shapes and reject others," Dan said. "In SmartROTO, we show what an arm looks like by giving the system a handful of keyframes to use as its base model. Every additional keyframe from the artist updates the model further. By the end, it has a solid understanding of the object and all the possible ways it deforms in the shot.” www.foundry.com